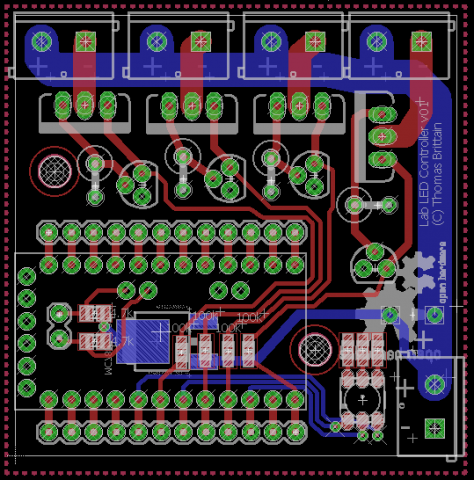
A little lab controller PCB I'm working on. It centers around four high-power constant current circuits meant to be driven by an Atmega328's PWM.
I hate working on anything mechanical in dim light; comes from dropping parts down under the engine when working on cars. I'm also pretty particular about my type of light. The "Cool White" or CFLs really bother me. I feel like I'm a bug headed towards a bug-zapper.
I have a few design goals,
- Warm white is the way to go. I'm shooting for four 1k lumen warm-white LEDs at 12v at ~1A.
- I've a plug ...






