
This is a build out of TX-601’s Coordinated Entry By-Name List. The report is written using SQLDF inside of an R environment.
Homebase Function
homebase <- function(
hmisDataPath,
vispdatDataPath,
staffInfoDataPath,
executionPath,
hmisFunctionsFilePath,
viSpdat2DataPath,
clientContactInfoPath) {
library("tcltk")
# Load the weights for progress bar
loadingPackagesIncrement <- 2
loadingHMISDataIncrement <- 10
addDisabilitiesIncrement <- 5
householdIdIncrement <- 4
calculatingAgeIncrement <- 1
gettingEnrollmentsIncrement <- 10
gettingStaffInfoIncrement <- 5
calculatingCHIncrement <- 10
addVispdatIncrement <- 5
getFamilyWithChildIncrement <- 5
loadServicesIncrement <- 15
nbnStaysIncrement <- 5
outreachContactsIncrement <- 5
outreachAndNbnCountIncrement <- 5
clientContactinfoIncrement <- 3
makeHmisCodesReadableIncrement <- 2
formatHomebaseIncrement <- 1
# Find the progress bar max.
total <- (loadingPackagesIncrement +
loadingHMISDataIncrement +
addDisabilitiesIncrement +
householdIdIncrement +
calculatingAgeIncrement +
gettingEnrollmentsIncrement +
gettingStaffInfoIncrement +
calculatingCHIncrement +
addVispdatIncrement +
getFamilyWithChildIncrement +
loadServicesIncrement +
nbnStaysIncrement +
outreachAndNbnCountIncrement +
makeHmisCodesReadableIncrement +
formatHomebaseIncrement +
clientContactinfoIncrement
)
# Initialize progress bar
pbCounter = 0
pb <- tkProgressBar(title = "Homebase Function", min = 0,
max = total, width = 300)
###### START ##########
setTkProgressBar(pb, pbCounter, label = "Loading Packages")
# There needs to be a lot of allocated memory for Java for
# XLConnect to work.
options(java.parameters = "-Xmx14336m") ## memory set to 14 GB
library(sqldf)
library(XLConnect)
library(xlsx)
# Load the HMIS functions.
source(hmisFunctionsFilePath)
# Return to execution path.
setwd(executionPath)
# Update progress bar
pbCounter <- pbCounter + loadingPackagesIncrement
setTkProgressBar(pb, pbCounter, label = "Loading HMIS Data")
# Load HMIS Data
client <- loadClient(hmisDataPath)
enrollment <- loadEnrollment(hmisDataPath)
disabilities <- loadDisabilities(hmisDataPath)
exit <- loadExit(hmisDataPath)
project <- loadProject(hmisDataPath)
enrollmentCoc <- loadEnrollmentCoc(hmisDataPath)
# Return to execution path.
setwd(executionPath)
pbCounter <- pbCounter + loadingHMISDataIncrement
setTkProgressBar(pb, pbCounter, label = "Getting Disabilities")
# Takes the Disabilities.csv and breaks out the disabilities reported
# for each participants into individual elements with binary resposnes.
client <- addDisabilityInfoToClient(client, disabilities)
# Update progress bar
pbCounter <- pbCounter + addDisabilitiesIncrement
setTkProgressBar(pb, pbCounter, label = "Getting Household IDs")
# Gets the PersonalIDs of participants with a HUD Entry or Update in last 90 days.
enrollmentCoc <- getMostRecentRecordsPerId(enrollmentCoc, "PersonalID", "DateCreated")
enrollmentCoc$DateCreated <- as.character(enrollmentCoc$DateCreated)
# Get Household IDs from EnrollmentCoc.csv
client_HHIDs <- sqldf("SELECT DISTINCT a.PersonalID, b.HouseholdID
FROM client a
LEFT JOIN enrollmentCoc b
ON a.PersonalID=b.PersonalID
WHERE HouseholdID != 'NA'
")
client_HHIDs <- sqldf("SELECT PersonalID, MAX(HouseholdID) As 'HouseholdID' FROM client_HHIDs GROUP BY PersonalID")
# Update progress bar
pbCounter <- pbCounter + householdIdIncrement
setTkProgressBar(pb, pbCounter, label = "Calculating Age")
# Calculate age
client <- sqldf("SELECT DISTINCT *, (DATE('NOW') - DATE(DOB)) As 'Age' FROM client")
pbCounter <- pbCounter + calculatingAgeIncrement
setTkProgressBar(pb, pbCounter, label = "Getting Enrollments")
# Filters to most recent HUD Assessment per participant
df1 <- getMostRecentRecordsPerId(enrollment, "PersonalID", "EntryDate")
## Adds a 'MaxEntryDate' flag to enrollment
#enrollment <- sqldf("SELECT a.*, b.MaxEntryDate
#FROM enrollment a
#LEFT JOIN df1 b
#ON a.ProjectEntryID=b.ProjectEntryID
#")
# Adds a 'MaxEntryDate' flag to enrollment
enrollment <- sqldf("SELECT a.*, b.MaxEntryDate
FROM enrollment a
LEFT JOIN df1 b
ON a.ProjectEntryID=b.ProjectEntryID
WHERE b.MaxEntryDate = 'Yes'
")
# Get Project Info for Enrollment
enrollmentCoc <- addProjectInfoToEnrollment(enrollmentCoc, project)
df3 <- sqldf("SELECT PersonalID, DateCreated As 'MostRecentHUDAssess', UserID As 'StaffID', ProjectName, ProjectType
FROM enrollmentCoc")
df3 <- makeProjectTypeReadable(df3)
pbCounter <- pbCounter + gettingStaffInfoIncrement
setTkProgressBar(pb, pbCounter, label = "Calculating Chronically Homeless")
# Adds a ChronicallyHomeless flag
df4 <- addChronicallyHomelessFlagToClient(client, df1)
# Adds a ActiveInPh flag
df5 <- getClientsInPH(loadEnrollment(hmisDataPath), exit, project)
# Returns flags to clientDf
targetClient <- sqldf("SELECT DISTINCT a.*, b.'ActiveInPh', c.EntryDate
FROM df4 a
LEFT JOIN df5 b
ON a.PersonalID=b.PersonalID
LEFT JOIN enrollment c
ON a.PersonalID=c.PersonalID
")
colnames(targetClient)[which(colnames(targetClient) == "EntryDate")] <- "RecentHUDEntryDate"
# Load staff information
staffInfo <- readWorksheetFromFile(staffInfoDataPath, sheet = 1, startRow = 1)
colnames(staffInfo)[1] <- "StaffID"
staffInfo <- sqldf("SELECT DISTINCT StaffID, Name, Email FROM staffInfo")
# Find the staff information for who completed each HUD Assessment.
df7 <- sqldf("SELECT a.*, b.Name As 'StaffName', b.Email As 'StaffEmail'
FROM df3 a
LEFT JOIN staffInfo b
ON a.StaffID=b.StaffID
")
remove(list = c("staffInfo"))
# Add the Staff and Project information back to client list.
targetClient <- sqldf("SELECT a.*, b.MostRecentHUDAssess, b.StaffName, b.StaffEmail, b.ProjectName As 'LastProgramInContact', b.ReadableProjectType As 'LastProjectTypeContacted'
FROM targetClient a
LEFT JOIN df7 b
ON a.PersonalID=b.PersonalID
")
targetClient <- subset(targetClient)
# Cleanup
remove(list = c("df4", "df3", "df5", "df1", "enrollmentCoc"))
pbCounter <- pbCounter + calculatingCHIncrement
setTkProgressBar(pb, pbCounter, label = "Adding VI-SPDAT")
# Load VI-SPDAT information
viSpdat <- readWorksheetFromFile(vispdatDataPath, sheet = 1, startRow = 1)
viSpdat2 <- readWorksheetFromFile(viSpdat2DataPath, sheet = 1, startRow = 1)
# Clean up VI-SPDAT1 formatting
colnames(viSpdat)[6] <- "DateOfVISPDAT"
viSpdat$DateOfVISPDAT <- as.character(viSpdat$DateOfVISPDAT)
viSpdat$Participant.Enterprise.Identifier <- gsub("-", "", viSpdat$Participant.Enterprise.Identifier)
viSpdat$Family.Enterprise.Identifier <- gsub("-", "", viSpdat$Family.Enterprise.Identifier)
viSpdat$Family.Enterprise.Identifier <- gsub("\\{", "", viSpdat$Family.Enterprise.Identifier)
viSpdat$Family.Enterprise.Identifier <- gsub("\\}", "", viSpdat$Family.Enterprise.Identifier)
colnames(viSpdat)[1] <- "PersonalID"
# Clean up VI-SPDAT2 formatting
viSpdat2$DateOfVISPDAT <- as.character(viSpdat2$DateOfVISPDAT)
viSpdat2$PersonalID <- gsub("-", "", viSpdat2$PersonalID)
# Get most recent VI-SPDAT per client.
viSpdat <- getMostRecentRecordsPerId(viSpdat, "PersonalID", "DateOfVISPDAT")
viSpdat2 <- getMostRecentRecordsPerId(viSpdat2, "PersonalID", "DateOfVISPDAT")
# Shape VI-SPDAT to look like VI-SPDAT 2
viSpdat <- sqldf("SELECT PersonalID, DateOfVISPDAT As 'DateOfVISPDAT', '' As VISPDATTotalFamilyScore, '' As VISPDATTotalYouthScore, ScoreVISPDAT As 'VISPDATTotalIndividualScore', 'Individual' As TypeOfViSpdat FROM viSpdat")
viSpdat2 <- sqldf("SELECT PersonalID, DateOfVISPDAT, VISPDATTotalFamilyScore, VISPDATTotalYouthScore, VISPDATTotalIndividualScore, TypeOfViSpdat FROM viSpdat2")
allVispdat <- rbind(viSpdat, viSpdat2)
# Get max between new and old VI-SPDAT
allVispdat <- getMostRecentRecordsPerId(allVispdat, "PersonalID", "DateOfVISPDAT")
allVispdat <- unique(allVispdat)
allVispdat$VISPDATTotalIndividualScore[allVispdat$VISPDATTotalIndividualScore == ''] <- '0'
allVispdat$VISPDATTotalFamilyScore[allVispdat$VISPDATTotalFamilyScore == ''] <- '0'
allVispdat$VISPDATTotalYouthScore[allVispdat$VISPDATTotalYouthScore == ''] <- '0'
allVispdat$VISPDATTotalIndividualScore[is.na(allVispdat$VISPDATTotalIndividualScore)] <- '0'
allVispdat$VISPDATTotalFamilyScore[is.na(allVispdat$VISPDATTotalFamilyScore)] <- '0'
allVispdat$VISPDATTotalYouthScore[is.na(allVispdat$VISPDATTotalYouthScore)] <- '0'
allVispdat$VISPDATTotalIndividualScore <- as.integer(allVispdat$VISPDATTotalIndividualScore)
allVispdat$VISPDATTotalFamilyScore <- as.integer(allVispdat$VISPDATTotalFamilyScore)
allVispdat$VISPDATTotalYouthScore <- as.integer(allVispdat$VISPDATTotalYouthScore)
allVispdat <- subset(allVispdat)
# Make one column for score.
#allVispdat <- sqldf("SELECT *, CASE
#WHEN (VISPDATTotalFamilyScore IS ''
#AND VISPDATTotalYouthScore IS '')
#THEN VISPDATTotalIndividualScore
#WHEN (VISPDATTotalFamilyScore IS ''
#AND VISPDATTotalIndividualScore IS '')
#THEN VISPDATTotalYouthScore
#ELSE VISPDATTotalFamilyScore
#END As 'ScoreVISPDAT'
#FROM allVispdat
#ORDER BY ScoreVISPDAT DESC
#")
allVispdat <- sqldf("SELECT *, CASE
WHEN (VISPDATTotalFamilyScore <= VISPDATTotalIndividualScore
AND VISPDATTotalYouthScore <= VISPDATTotalIndividualScore)
THEN VISPDATTotalIndividualScore
WHEN (VISPDATTotalFamilyScore <= VISPDATTotalYouthScore
AND VISPDATTotalIndividualScore <= VISPDATTotalYouthScore)
THEN VISPDATTotalYouthScore
ELSE VISPDATTotalFamilyScore
END As 'ScoreVISPDAT'
FROM allVispdat
ORDER BY ScoreVISPDAT DESC
")
allVispdat$ScoreVISPDAT <- as.numeric(allVispdat$ScoreVISPDAT)
targetClient <- subset(targetClient)
# Add VI-SPDAT scores and dates to the client list.
targetClient <- sqldf("SELECT a.*, b.ScoreVISPDAT, b.DateOfVISPDAT, b.TypeOfVispdat
FROM targetClient a
LEFT JOIN allVispdat b
ON a.PersonalID=b.PersonalID
")
# Just in case, make date SQLite friendly.
targetClient$DateOfVISPDAT <- as.character(targetClient$DateOfVISPDAT)
remove(list = c("viSpdat", "viSpdat2", "allVispdat"))
pbCounter <- pbCounter + addVispdatIncrement
setTkProgressBar(pb, pbCounter, label = "Getting Family with Child")
client <- sqldf("SELECT a.*, b.HouseholdID
FROM client a
LEFT JOIN client_HHIDs b
ON a.PersonalID=b.PersonalID")
targetClient <- sqldf("SELECT a.*, b.HouseholdID
FROM targetClient a
LEFT JOIN client_HHIDs b
ON a.PersonalID=b.PersonalID")
remove(client)
remove(enrollment)
client <- loadClient(hmisDataPath)
enrollment <- loadEnrollment(hmisDataPath)
family_flag_builder <- sqldf("SELECT DISTINCT PersonalID, HouseholdID, RelationshipToHoH FROM enrollment")
family_flag_builder <- family_flag_builder[!is.na(family_flag_builder$HouseholdID),]
family_flag_builder <- sqldf("SELECT HouseholdID,
(CASE WHEN RelationshipToHoH = 1 THEN 'Yes' ELSE 'No' END) As 'Adult',
(CASE WHEN RelationshipToHoH = 2 THEN 'Yes' ELSE 'No' END) As 'Child'
FROM family_flag_builder")
hhids_of_adults <- sqldf("SELECT DISTINCT HouseholdID, Adult FROM family_flag_builder WHERE Adult = 'Yes'")
hhids_of_child <- sqldf("SELECT DISTINCT HouseholdID, Child FROM family_flag_builder WHERE Child = 'Yes'")
family_flag_builder <- sqldf("SELECT a.HouseholdID, a.Adult, b.Child
FROM hhids_of_adults a
INNER JOIN hhids_of_child b
ON a.HouseholdID=b.HouseholdID
")
family_flag_builder <- sqldf("SELECT HouseholdID, 'Yes' As FamilyWithChildren FROM family_flag_builder WHERE Adult = 'Yes' AND Child = 'Yes' GROUP BY HouseholdID")
# Add the family flag back to the client list.
targetClient <- sqldf("SELECT DISTINCT a.*, b.FamilyWithChildren
FROM targetClient a
LEFT JOIN family_flag_builder b
ON a.HouseholdID=b.HouseholdID
")
remove(list = c("family_flag_builder"))
targetClient <- subset(targetClient)
pbCounter <- pbCounter + getFamilyWithChildIncrement
setTkProgressBar(pb, pbCounter, label = "Loading Services")
# Free up some memory before attempting Services.csv
remove(list = c("client", "enrollment", "disabilities", "exit", "project"))
setwd(hmisDataPath)
# Load services -- large files.
services <- loadServices()
pbCounter <- pbCounter + loadServicesIncrement
setTkProgressBar(pb, pbCounter, label = "Getting Night-by-Night Stays")
# Get all of te NBN service entries.
clientNbn <- sqldf("SELECT *
FROM services
WHERE RecordType = 200
")
# Count the number of NBN check-ins per client. Make sure the date as distinct, due to ETO duplicate bed
# stays when data is pulled using a program-group including two-shelters.
daysCheckedInNBN <- sqldf("SELECT DISTINCT(PersonalID), COUNT (DISTINCT(DateProvided)) As 'NonProgramShelterNights'
FROM clientNbn
GROUP BY PersonalID
")
pbCounter <- pbCounter + nbnStaysIncrement
setTkProgressBar(pb, pbCounter, label = "Getting Outreach Contacts")
# Get all Outreach Contact services.
clientOutreach <- sqldf("SELECT *
FROM services
WHERE RecordType = 12
")
# Count all Outreach Contacts per client. Count distinct is to get around ETO bug when data is
# pulled using a program group which includes two outreach agencies.
outreachContacts <- sqldf("SELECT DISTINCT(PersonalID), COUNT (DISTINCT(DateProvided)) As 'NumberOutreachContacts'
FROM clientOutreach
GROUP BY PersonalID
")
pbCounter <- pbCounter + outreachContactsIncrement
setTkProgressBar(pb, pbCounter, label = "Adding Outreach and NBN Count")
# Add NBN stays to client list.
targetClient <- sqldf("SELECT a.*, b.NonProgramShelterNights
FROM targetClient a
LEFT JOIN daysCheckedInNBN b
ON a.PersonalID=b.PersonalID
")
# Add Outreach Contacts to client list.
targetClient <- sqldf("SELECT a.*, b.NumberOutreachContacts
FROM targetClient a
LEFT JOIN outreachContacts b
ON a.PersonalID=b.PersonalID
")
remove(list = c("services", "clientOutreach", "daysCheckedInNBN", "clientNbn", "outreachContacts"))
pbCounter <- pbCounter + outreachAndNbnCountIncrement
setTkProgressBar(pb, pbCounter, label = "Add Client Contact Info")
# Add client contact information
clientContactInfo <- readWorksheetFromFile(clientContactInfoPath, sheet = 1, startRow = 1)
colnames(clientContactInfo)[1] <- "PersonalID"
colnames(clientContactInfo)[2] <- "ProgramStartDate"
colnames(clientContactInfo)[3] <- "ClientEmail"
colnames(clientContactInfo)[4] <- "ClientPhone"
clientContactInfo$PersonalID <- gsub("-", "", clientContactInfo$PersonalID)
clientContactInfo <- getMostRecentRecordsPerId(clientContactInfo, "PersonalID", "ProgramStartDate")
targetClient <- sqldf("SELECT a.*, b.ClientEmail, b.ClientPhone
FROM targetClient a
LEFT JOIN clientContactInfo b
ON a.PersonalID=b.PersonalID
")
pbCounter <- pbCounter + clientContactinfoIncrement
setTkProgressBar(pb, pbCounter, label = "Make HMIS Codes Readable")
setwd(executionPath)
# Make HMIS codes human readable.
targetClient <- combineRaceColumnsAndMakeReadable(targetClient)
targetClient <- makeGenderReadable(targetClient)
targetClient <- makeEthnicityReadable(targetClient)
targetClient <- makeVeteranStatusReadable(targetClient)
pbCounter <- pbCounter + makeHmisCodesReadableIncrement
setTkProgressBar(pb, pbCounter, label = "Format Homebase Dataframe")
# Pull and format the client list.
homebase_all <- sqldf("SELECT DISTINCT
PersonalID,
FirstName,
MiddleName,
LastName,
ClientEmail,
ClientPhone,
NameSuffix,
SSN,
DOB,
Age,
Gender,
Race,
Ethnicity,
VeteranStatus,
HouseholdID,
ChronicallyHomeless,
NumberOutreachContacts,
NonProgramShelterNights,
RecentHUDEntryDate,
MostRecentHUDAssess,
FamilyWithChildren,
ScoreVISPDAT,
TypeOfViSpdat,
DateOfVISPDAT,
PhysicalDisability,
DevelopmentalDisability,
ChronicHealthCondition,
a.'HIV/AIDS',
MentalHealthProblem,
SubstanceAbuse,
StaffName,
StaffEmail,
LastProgramInContact,
LastProjectTypeContacted,
ActiveInPH
FROM targetClient a
")
pbCounter <- pbCounter + formatHomebaseIncrement
setTkProgressBar(pb, pbCounter, label = "Homebase Complete")
# Clean up
close(pb)
rm(list = setdiff(ls(), "homebase_all"))
# Retun list.
homebase_all
}Homebase Report
options(java.parameters = "-Xmx14336m") ## memory set to 14 GB
developmentLog <- c("REPORT DETAILS -- DO NOT DELETE THIS TAB",
"For development information please visit ladvien.com",
"5/30/17",
"Added order by for PSH and RRH -- should match operations manual.",
"Changed 90-day filter for VI-SPDAT to only need at least one VI-SPDAT to keep participant in 'active'",
"Added client contact information",
"5/10/2017",
"Changed EnrollmentCoC max date function to look at DateCreated not InformationDate",
"Changed the Enrollment max date function to look at EntryDate and not DateCreated",
"",
"05/07/2017",
"Automated Formatting",
"Added descending on VeteranStatus, FamilyWithChildren, ScoreVISPDAT in respective order.",
"Added Graphic Dashboard",
"",
"05/07/2017",
"Switched from using Client.DOB -> Age for establishing family to Enrollment.RelationshipToHoH. This seems to have addressed the families not flagging.",
"",
"03/15/2017",
"Incorporated VI-SPDAT2",
"",
"02/01/2017",
"Initial Report",
""
)
# Argument guide
# 1 = Name of Report
# 2 = Folder path for HMIS data
# 3 = VI-SPDAT File data
# 4 = Staff Info File data
# 5 = Executing directory path
# args <- commandArgs(trailingOnly = TRUE)
# nameOfReport <- args[1]
# hmisDataPath <- args[2]
# vispdatDataPath <- args[3]
# staffInfoDataPath <- args[4]
# executionPath <- args[5]
# viSpdat2DataPath <- args[6]
#
# outputPath <- executionPath
# homebaseFunctionFilePath <- paste(executionPath, "\\Homebase_Function.R", sep ="")
# hmisFunctionsFilePath <- paste(executionPath, "\\HMIS_R_Functions.R", sep = "")
# PC
nameOfReport <- "Homebase_Report.R"
hmisDataPath <- "E:/Dropbox/HMIS/Warehouse/All Program 2016 Program Group 3-1-2017 - 5-30-2017"
vispdatDataPath <- "E:/Dropbox/HMIS/Warehouse/VI-SPDAT and HUD Flat Export for SQL -- 3-6-2017.xlsx"
staffInfoDataPath <- "E:/Dropbox/HMIS/Warehouse/Staff Contact Info for SQL -- 3-6-2017.xlsx"
executionPath <- "E:/Dropbox/HMIS/Coordinated_Entry_Report"
hmisFunctionsFilePath <- "E:/Dropbox/HMIS/HMIS_R_Functions/HMIS_R_Functions.R"
homebaseFunctionFilePath <- "E:/Dropbox/HMIS/Coordinated_Entry_v2_TX-601/Coordinated_Entry_v2_TX-601/Homebase_Function.R"
outputPath <- "E:/Dropbox/HMIS/Warehouse"
viSpdat2DataPath <- "E:/Dropbox/HMIS/Warehouse/VI-SPDAT v2.0 -- 04-05-17 -- TB.xlsx"
clientContactInfoPath <- "E:/Dropbox/HMIS/Warehouse/Client Contact for SQL -- 5-30-17 -- TB.xlsx"
outputPath <- "E:/Dropbox/HMIS/Warehouse"
# Mac PC
#nameOfReport <- "Homebase_Report.R"
#hmisDataPath <- "C:/Users/Ladvien/Desktop/Homebase 04-18-2017/data"
#vispdatDataPath <- "C:/Users/Ladvien/Dropbox/HMIS/Warehouse/VI-SPDAT and HUD Flat Export for SQL -- 3-6-2017.xlsx"
#staffInfoDataPath <- "C:/Users/Ladvien/Dropbox/HMIS/Warehouse/Staff Contact Info for SQL -- 3-6-2017.xlsx"
#executionPath <- "C:/Users/Ladvien/Dropbox/HMIS/Coordinated_Entry_Report"
#hmisFunctionsFilePath <- "C:/Users/Ladvien/Dropbox/HMIS/HMIS_R_Functions/HMIS_R_Functions.R"
#homebaseFunctionFilePath <- "C:/Users/Ladvien/Dropbox/HMIS/Coordinated_Entry_v2_TX-601/Coordinated_Entry_v2_TX-601/Homebase_Function.R"
#viSpdat2DataPath <- "C:/Users/Ladvien/Dropbox/HMIS/Warehouse/VI-SPDAT v2.0 -- 04-05-17 -- TB.xlsx"
#outputPath <- "C:/Users/Ladvien/Desktop"
# Mac
#nameOfReport <- "Homebase_Report.R"
#hmisDataPath <- "/Users/user/Dropbox/HMIS/Coordinated_Entry_Report/All Programs 12-18-2016 to 03-18-2017"
#vispdatDataPath <- "/Users/user/Dropbox/HMIS/Coordinated_Entry_Report/VI-SPDAT and HUD Flat Export for SQL -- 3-6-2017.xlsx"
#staffInfoDataPath <- "/Users/user/Dropbox/HMIS/Coordinated_Entry_Report/Staff Contact Info for SQL -- 3-6-2017.xlsx"
#executionPath <- "/Users/user/Dropbox/HMIS/Coordinated_Entry_Report"
#hmisFunctions <- "/Users/user/Dropbox/HMIS/HMIS_R_Functions/HMIS_R_Functions.R"
cat("arg1: ")
cat(nameOfReport)
cat("\n")
cat("arg2: ")
cat(hmisDataPath)
cat("\n")
cat("arg3: ")
cat(vispdatDataPath)
cat("\n")
cat("arg4: ")
cat(staffInfoDataPath)
cat("\n")
cat("arg5: ")
cat(executionPath)
cat("\n")
cat("arg6: ")
cat(viSpdat2DataPath)
cat("\n")
source(homebaseFunctionFilePath)
homebase_all <- homebase(hmisDataPath,
vispdatDataPath,
staffInfoDataPath,
executionPath,
hmisFunctionsFilePath,
viSpdat2DataPath,
clientContactInfoPath)
######## WIP: Aggregates ##########
numberOfHudAssessmentsPerStaff <- sqldf("SELECT StaffName, COUNT(StaffName) FROM homebase_all GROUP BY StaffName")
#countOfChronicallyHomeless <- sqldf("SELECT COUNT(PersonalID) As CountOfChronic FROM homebase_all WHERE ChronicallyHomeless = 'Yes'")
#countOfGender <- sqldf("SELECT DISTINCT(Gender), COUNT(Gender) FROM homebase_all GROUP BY Gender")
#ageCounts <- sqldf("SELECT CASE
#WHEN Age < 5 THEN 1
#WHEN Age > 4 AND Age < 13 THEN 2
#WHEN Age > 13 AND Age < 18 THEN 3
#WHEN Age > 17 AND Age < 25 THEN 4
#WHEN Age > 24 AND Age < 35 THEN 5
#WHEN Age > 34 AND Age < 45 THEN 6
#WHEN Age > 44 AND Age < 55 THEN 7
#WHEN Age > 54 AND Age < 62 THEN 8
#WHEN Age > 61 THEN 9
#END As AgeType
#FROM homebase_all
#")
#aggregates <- cbind(numberOfHudAssessmentsPerStaff, countOfChronicallyHomeless)
homebase_housed <- sqldf("SELECT *
FROM homebase_all
WHERE ActiveInPH IS 'Yes'
ORDER BY VeteranStatus DESC,
FamilyWithChildren DESC,
ScoreVISPDAT DESC
")
# Filter client to PersonalIDs with Entry or Update in last 90 days
homebase_active <- sqldf("SELECT *
FROM homebase_all
WHERE (
RecentHUDEntryDate > DATE('NOW', '-90 DAY')
OR (MostRecentHUDAssess > DATE('NOW', '-90 DAY'))
)
AND
(
(DateOfVISPDAT != '')
)
AND
ActiveInPH IS NOT 'Yes'
ORDER BY VeteranStatus DESC,
FamilyWithChildren DESC,
ScoreVISPDAT DESC
")
tmp_possibly_active <- sqldf("SELECT *
FROM homebase_all
WHERE (( MostRecentHUDAssess > DATE('NOW', '-90 DAY'))
OR
(
(DateOfVISPDAT > DATE('NOW', '-90 DAY'))
))
AND
ActiveInPH IS NOT 'Yes'
ORDER BY VeteranStatus DESC,
FamilyWithChildren DESC,
ScoreVISPDAT DESC
")
homebase_possibly_active <- sqldf("SELECT a.*
FROM tmp_possibly_active a
LEFT JOIN homebase_active b
ON a.PersonalID=b.PersonalID
WHERE b.PersonalID IS NULL
ORDER BY VeteranStatus DESC,
FamilyWithChildren DESC,
ScoreVISPDAT DESC
")
homebase_psh <- sqldf("SELECT *
FROM homebase_active
WHERE ChronicallyHomeless = 'Yes'
ORDER BY MostRecentHUDAssess DESC
")
homebase_psh <- sqldf("SELECT * FROM homebase_psh ORDER BY
ScoreVISPDAT DESC,
NonProgramShelterNights DESC
")
homebase_rrh <- sqldf("SELECT *
FROM homebase_active
WHERE ChronicallyHomeless IS NOT 'Yes'
")
tmp_rrh_vets <- sqldf("SELECT * FROM homebase_rrh WHERE VeteranStatus = 'Yes'")
tmp_rrh_youth <- sqldf("SELECT * FROM homebase_rrh WHERE Age > 17 AND Age < 26")
tmp_rrh_families <- sqldf("SELECT * FROM homebase_rrh WHERE FamilyWithChildren = 'Yes'")
tmp_rrh_singles <- sqldf("SELECT * FROM homebase_rrh WHERE VeteranStatus IS NOT 'Yes'
AND FamilyWithChildren IS NOT 'Yes'
AND Age < 18 OR Age > 25
")
tmp_rrh_vets <- sqldf("SELECT * FROM tmp_rrh_vets ORDER BY
ScoreVISPDAT DESC,
NonProgramShelterNights DESC,
MostRecentHUDAssess DESC
")
tmp_rrh_youth <- sqldf("SELECT * FROM tmp_rrh_youth ORDER BY
ScoreVISPDAT DESC,
NonProgramShelterNights DESC,
MostRecentHUDAssess DESC
")
tmp_rrh_families <- sqldf("SELECT * FROM tmp_rrh_families ORDER BY
ScoreVISPDAT DESC,
NonProgramShelterNights DESC,
MostRecentHUDAssess DESC
")
tmp_rrh_singles <- sqldf("SELECT * FROM tmp_rrh_singles ORDER BY
ScoreVISPDAT DESC,
NonProgramShelterNights DESC,
MostRecentHUDAssess DESC
")
homebase_rrh <- rbind(tmp_rrh_vets, tmp_rrh_youth, tmp_rrh_families, tmp_rrh_singles)
homebase_assistToList <- sqldf("SELECT DISTINCT StaffName, COUNT(StaffName) As 'AssistToList'
FROM homebase_active
WHERE ActiveInPH IS NOT 'Yes'
GROUP BY StaffName
ORDER BY AssistToList DESC
")
#library("ggplot2")
#df1 <- homebase_all$LastProjectTypeContacted
#ggplot(homebase_all, aes(NumberOutreachContacts, LastProgramInContact)) +
#geom_raster(aes(fill = Age), interpolate = FALSE)
detach("package:XLConnect", unload = TRUE)
detach("package:xlsx", unload = TRUE)
library(openxlsx)
reportDetails <- data.frame(developmentLog)
colnames(reportDetails)[1] <- "Development Log"
ch_count <- sqldf("SELECT 'Chronically\nHomeless' As 'Category',
SUM(CASE ChronicallyHomeless WHEN 'Yes' THEN 1 ELSE 0 END) As 'Count'
FROM homebase_psh")
vet_count <- sqldf("SELECT 'Veteran' As 'Category',
SUM(CASE VeteranStatus WHEN 'Yes' THEN 1 ELSE 0 END) As 'Count'
FROM homebase_psh")
female_count <- sqldf("SELECT 'Female' As 'Category',
SUM(CASE Gender WHEN 'Female' THEN 1 ELSE 0 END) As 'Count'
FROM homebase_psh")
male_count <- sqldf("SELECT 'Male' As 'Category',
SUM(CASE Gender WHEN 'Male' THEN 1 ELSE 0 END) As 'Count'
FROM homebase_psh")
development_count <- sqldf("SELECT 'Developmental\nDisability' As 'Category',
SUM(CASE DevelopmentalDisability WHEN 'Yes' THEN 1 ELSE 0 END) As 'Count'
FROM homebase_psh")
chronic_health_count <- sqldf("SELECT 'Chronic Health\nCondition' As 'Category',
SUM(CASE ChronicHealthCondition WHEN 'Yes' THEN 1 ELSE 0 END) As 'Count'
FROM homebase_psh")
hiv_aids_count <- sqldf("SELECT 'HIV/AIDS' As 'Category',
SUM(CASE 'HIV/AIDS' WHEN 'Yes' THEN 1 ELSE 0 END) As 'Count'
FROM homebase_psh")
mental_health_count <- sqldf("SELECT 'Mental Health\nProblem' As 'Category',
SUM(CASE MentalHealthProblem WHEN 'Yes' THEN 1 ELSE 0 END) As 'Count'
FROM homebase_psh")
substance_abuse_count <- sqldf("SELECT 'Substance\nAbuse' As 'Category',
SUM(CASE SubstanceAbuse WHEN 'Yes' THEN 1 ELSE 0 END) As 'Count'
FROM homebase_psh")
#fleeing_dv_count <-
family_count <- sqldf("SELECT 'Family With Children' As 'Category',
SUM(CASE FamilyWithChildren WHEN 'Yes' THEN 1 ELSE 0 END) As 'Count'
FROM homebase_psh")
counts <- rbind(ch_count,
vet_count,
female_count,
male_count,
development_count,
chronic_health_count,
hiv_aids_count,
mental_health_count,
substance_abuse_count,
family_count)
counts$val <- seq()
counts$Category <- factor(counts$Category, levels = counts$Category[order(counts$val)])
###########################################
# Calculate Housing Vacancy #
###########################################
project <- loadProject(hmisDataPath)
enrollment <- loadEnrollment(hmisDataPath)
exit <- loadExit(hmisDataPath)
inventory <- loadInventory(hmisDataPath)
enrollmentAndProject <- addProjectInfoToEnrollment(enrollment, project)
activeInHousing <- sqldf("SELECT a.ProjectEntryID, a.PersonalID, a.ProjectType, a.ProjectName, a.ProjectID, b.ExitDate
FROM enrollmentAndProject a
LEFT JOIN exit b
ON a.ProjectEntryID=b.ProjectEntryID
WHERE (a.ProjectType = 2 OR a.ProjectType = 3 OR a.ProjectType = 9 OR a.ProjectType = 13)
")
activeInHousing$ExitDate[is.na(activeInHousing$ExitDate)] <- 0
activeInHousing <- sqldf("SELECT DISTINCT * FROM activeInHousing WHERE ExitDate = 0")
aggregatedActiveInHousing <- sqldf("SELECT ProjectName, ProjectID, COUNT(ProjectName) As 'Enrolled'
FROM activeInHousing
GROUP BY ProjectName
ORDER BY Enrolled DESC")
tmp <- sqldf("SELECT ProjectID, SUM(HMISParticipatingBeds) As 'Beds' FROM inventory GROUP BY ProjectID")
aggregatedActiveInHousing <- sqldf("SELECT a.*, b.Beds
FROM aggregatedActiveInHousing a
LEFT JOIN tmp b
ON a.ProjectID=b.ProjectID
")
projectVacancy <- sqldf("SELECT ProjectName, Enrolled, Beds, (CAST(Enrolled As FLOAT) / CAST(Beds As Float)) As 'OccupancyPercentage' FROM aggregatedActiveInHousing ORDER BY 'Vacancy %' DESC")
projectVacancy <- projectVacancy[order(projectVacancy$OccupancyPercentage),]
projectVacancy <- subset(projectVacancy)
projectWithVacancy <- sqldf("SELECT * FROM projectVacancy WHERE OccupancyPercentage < 1")
projectWithVacancy <- subset(projectWithVacancy)
###########################################
# Create some Awesome Graphs #
###########################################
library("ggplot2")
library("RColorBrewer")
png("rrhCountsGraph.png", height = 1200, width = 1200, res = 250, pointsize = 8)
rrhCountsGraph <- ggplot(data = counts, aes(x = Category, y = Count, fill = Category)) +
geom_bar(stat = "identity") +
labs(title = "Permanent Supportive Housing Eligibe") +
theme(axis.text.x = element_text(angle = 45, hjust = 1),
legend.position = "none") +
scale_fill_brewer(palette = "Spectral")
dev.off()
n <- 60
qual_col_pals = brewer.pal.info[brewer.pal.info$category == 'qual',]
col_vector = unlist(mapply(brewer.pal, qual_col_pals$maxcolors, rownames(qual_col_pals)))
levels <- seq(nrow(projectVacancy))
projectVacancy$Order <- levels
png("projectVacancy.png", height = 1200, width = 1200, res = 250, pointsize = 8)
projectVacancyGraph <- ggplot(data = projectVacancy, aes(x = reorder(ProjectName, -projectVacancy$Order), y = OccupancyPercentage, fill = ProjectName)) +
geom_bar(stat = "identity") +
labs(title = "Occupancy by Housing Projects") +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
legend.position = "none") +
coord_flip()
dev.off()
print(projectVacancyGraph)
n <- 60
qual_col_pals = brewer.pal.info[brewer.pal.info$category == 'qual',]
col_vector = unlist(mapply(brewer.pal, qual_col_pals$maxcolors, rownames(qual_col_pals)))
levels <- seq(nrow(projectWithVacancy))
projectWithVacancy$Order <- levels
vacancyPal <- c("#70AD47", "#47A3AD", "#AD5147", "#8447AD")
png("projectWithVacancy.png", height = 1200, width = 1200, res = 250, pointsize = 8)
projectWithVacancyGraph <- ggplot(data = projectWithVacancy,
aes(x = reorder(ProjectName, Order), y = OccupancyPercentage, fill = OccupancyPercentage)) +
geom_bar(stat = "identity", width = 1, color = vacancyPal[4]) +
scale_fill_gradient2(low = "green", mid = vacancyPal[1], high = vacancyPal[2]) +
labs(title = "Occupancy by Project") +
xlab("Current Occupancy %") +
ylab("Occupancy %") +
theme(axis.text.x = element_text(angle = 90, hjust = 1, size = 16),
axis.text.y = element_text(hjust = 1),
legend.position = "none") +
coord_flip()
dev.off()
ggsave("projectWithVacancy.png")
print(projectWithVacancyGraph)
###########################################
# Format Workbook, Add Graphs, and Write #`
###########################################
library("openxlsx")
setwd(outputPath)
# Theme
color_column_background <- "#70AD47"
color_header_font_color <- "#FFFFFF"
column_header_font_size <- 18
## Header Styles
headerStyle1 <- createStyle(fgFill = color_column_background,
valign = "top",
halign = "CENTER",
fontColour = color_header_font_color,
fontSize = column_header_font_size)
# Create the Workbook
homebaseWorkbook <- createWorkbook()
# Add the needed sheets.
addWorksheet(homebaseWorkbook, sheetName = "Dashboard")
addWorksheet(homebaseWorkbook, sheetName = "EligibleForPSH")
addWorksheet(homebaseWorkbook, sheetName = "EligibleForRRH")
addWorksheet(homebaseWorkbook, sheetName = "Possibly Active")
addWorksheet(homebaseWorkbook, sheetName = "Housed")
addWorksheet(homebaseWorkbook, sheetName = "AssistToList")
addWorksheet(homebaseWorkbook, sheetName = "Report Details")
# Add the data to worksheets.
writeDataTable(homebaseWorkbook, sheet = 2, x = homebase_psh, colNames = TRUE, tableStyle = "TableStyleLight9", headerStyle = headerStyle1)
writeDataTable(homebaseWorkbook, sheet = 3, x = homebase_rrh, colNames = TRUE, tableStyle = "TableStyleLight9", headerStyle = headerStyle1)
writeDataTable(homebaseWorkbook, sheet = 4, x = homebase_possibly_active, colNames = TRUE, tableStyle = "TableStyleLight9", headerStyle = headerStyle1)
writeDataTable(homebaseWorkbook, sheet = 5, x = homebase_housed, colNames = TRUE, tableStyle = "TableStyleLight9", headerStyle = headerStyle1)
writeDataTable(homebaseWorkbook, sheet = 6, x = homebase_assistToList, colNames = TRUE, tableStyle = "TableStyleLight9", headerStyle = headerStyle1)
writeDataTable(homebaseWorkbook, sheet = 7, x = reportDetails, colNames = TRUE, tableStyle = "TableStyleLight9", headerStyle = headerStyle1)
# Format the columns for readability.
setColWidths(homebaseWorkbook, 2, cols = 2:ncol(homebase_psh), widths = "auto")
setColWidths(homebaseWorkbook, 3, cols = 2:ncol(homebase_rrh), widths = "auto")
setColWidths(homebaseWorkbook, 4, cols = 2:ncol(homebase_possibly_active), widths = "auto")
setColWidths(homebaseWorkbook, 5, cols = 2:ncol(homebase_housed), widths = "auto")
setColWidths(homebaseWorkbook, 6, cols = 2:ncol(homebase_assistToList), widths = "auto")
setColWidths(homebaseWorkbook, 7, cols = 2:ncol(reportDetails), widths = "auto")
# Format first column statically. For some reason, 'auto' clips the PersonalID
setColWidths(homebaseWorkbook, 2, cols = 1:1, widths = 38)
setColWidths(homebaseWorkbook, 3, cols = 1:1, widths = 38)
setColWidths(homebaseWorkbook, 4, cols = 1:1, widths = 38)
setColWidths(homebaseWorkbook, 5, cols = 1:1, widths = 38)
setColWidths(homebaseWorkbook, 6, cols = 1:1, widths = 38)
setColWidths(homebaseWorkbook, 2, cols = 1:1, widths = 38)
# Format rows.
setRowHeights(homebaseWorkbook, 2, rows = 1:1, height = 40)
setRowHeights(homebaseWorkbook, 3, rows = 1:1, height = 40)
setRowHeights(homebaseWorkbook, 4, rows = 1:1, height = 40)
setRowHeights(homebaseWorkbook, 5, rows = 1:1, height = 40)
setRowHeights(homebaseWorkbook, 6, rows = 1:1, height = 40)
setRowHeights(homebaseWorkbook, 7, rows = 1:1, height = 40)
# Freeze the top row
freezePane(homebaseWorkbook, sheet = 2, firstRow = TRUE)
freezePane(homebaseWorkbook, sheet = 3, firstRow = TRUE)
freezePane(homebaseWorkbook, sheet = 4, firstRow = TRUE)
freezePane(homebaseWorkbook, sheet = 5, firstRow = TRUE)
freezePane(homebaseWorkbook, sheet = 6, firstRow = TRUE)
##################################
#### Add Graphs to Workbook ######
##################################
print(rrhCountsGraph) #plot needs to be showing
insertPlot(homebaseWorkbook, 1, width = 7.87, height = 5.5, fileType = "png", units = "in")
# Openxlsx requires zip.exe to save the workbook. Weird.
Sys.setenv("R_ZIPCMD" = "C:/Rtools/bin/zip.exe")
today <- Sys.Date()
print(outputPath)
saveWorkbook(homebaseWorkbook, paste(outputPath, "\\", "Homebase_v2_", today, ".xlsx", sep =""), overwrite = TRUE)
cat(getwd())
openXL(paste(outputPath, "\\", "Homebase_v2_", today, ".xlsx", sep = ""))The whole thing relies on some R functions I’ve written to assist:
HMIS Functions
# Thanks SO.
# http://stackoverflow.com/questions/9341635/check-for-installed-packages-before-running-install-packages
pkgTest <- function(x)
{
if (!require(x,character.only = TRUE))
{
install.packages(x,dep=TRUE)
library(x, character.only = TRUE)
if(!require(x,character.only = TRUE)) stop("Package not found")
} else {
library(x, character.only = TRUE)
}
}
pkgTest("sqldf")
pkgTest("tcltk")
pkgTest("zoo")
pkgTest("XLConnect")
loadAffiliation <- function(path = getwd()){
affiliation <- read.csv(paste(path, "/Affiliation.csv", sep = ""))
}
loadClient <- function(path = getwd()){
client <- read.csv(paste(path, "/Client.csv", sep = ""))
}
loadDisabilities <- function(path = getwd()) {
disabilities <- read.csv(paste(path, "/Disabilities.csv", sep = ""))
}
loadEmployementEducation <- function(path = getwd()) {
employementEducation <- read.csv(paste(path, "/EmploymentEducation.csv", sep = ""))
}
loadEnrollment <- function(path = getwd()) {
enrollment <- read.csv(paste(path, "/Enrollment.csv", sep = ""))
}
loadEnrollmentCoc <- function(path = getwd()) {
enrollmentCoc <- read.csv(paste(path, "/EnrollmentCoC.csv", sep = ""))
}
loadExit <- function(path = getwd()) {
exit <- read.csv(paste(path, "/Exit.csv", sep = ""))
}
loadExport <- function(path = getwd()) {
export <- read.csv(paste(path, "/Export.csv", sep = ""))
}
loadFunder <- function(path = getwd()){
funder <- read.csv(paste(path, "/Funder.csv", sep = ""))
}
loadHealthAndDv <- function(path = getwd()){
healthAndDv <- read.csv(paste(path, "/HealthAndDV.csv", sep = ""))
}
loadIncomeBenefits <- function(path = getwd()){
incomeBenefits <- read.csv(paste(path, "/IncomeBenefits.csv", sep = ""))
}
loadInventory <- function(path = getwd()){
inventory <- read.csv(paste(path, "/Inventory.csv", sep = ""))
}
loadOrganization <- function(path = getwd()){
organization <- read.csv(paste(path, "/Organization.csv", sep = ""))
}
loadProject <- function(path = getwd()){
project <- read.csv(paste(path, "/Project.csv", sep = ""))
}
loadProjectCoc <- function(path = getwd()){
projectCoc <- read.csv(paste(path, "/ProjectCoC.csv", sep = ""))
}
loadServices <- function(path = getwd()){
services <- read.csv(paste(path, "/Services.csv", sep = ""))
}
loadSite <- function(path = getwd()){
site <- read.csv(paste(path, "/Site.csv", sep = ""))
}
# loadHMISCsvs51 <- function(path) {
# affiliation <- read.csv(paste(path, "/Affiliation.csv", sep = ""))
# client <- read.csv(paste(path, "/Client.csv", sep = ""))
# disabilities <- read.csv(paste(path, "/Disabilities.csv", sep = ""))
# employementEducation <- read.csv(paste(path, "/EmploymentEducation.csv", sep = ""))
# enrollment <- read.csv(paste(path, "/Enrollment.csv", sep = ""))
# exit <- read.csv(paste(path, "/Exit.csv", sep = ""))
# export <- read.csv(paste(path, "/Export.csv", sep = ""))
# funder <- read.csv(paste(path, "/Funder.csv", sep = ""))
# healthAndDv <- read.csv(paste(path, "/HealthAndDV.csv", sep = ""))
# incomeBenefits <- read.csv(paste(path, "/IncomeBenefits.csv", sep = ""))
# inventory <- read.csv(paste(path, "/Inventory.csv", sep = ""))
# organization <- read.csv(paste(path, "/Organization.csv", sep = ""))
# project <- read.csv(paste(path, "/Project.csv", sep = ""))
# projectCoc <- read.csv(paste(path, "/ProjectCoC.csv", sep = ""))
# services <- read.csv(paste(path, "/Services.csv", sep = ""))
# site <- read.csv(paste(path, "/Site.csv", sep = ""))
# return(c(services, site))
# }
makeDestinationReadable <- function (df) {
df <- exit
df <- sqldf("SELECT *, Destination as 'ReadableDestination' FROM df")
df$ReadableDestination[df$ReadableDestination == "1"] <- "Emergency shelter, including hotel or motel paid for with emergency shelter voucher"
df$ReadableDestination[df$ReadableDestination == "2"] <- "Transitional housing for homeless persons (including homeless youth)"
df$ReadableDestination[df$ReadableDestination == "3"] <- "Permanent housing for formerly homeless persons (such as: CoC project; or HUD legacy programs; or HOPWA PH)"
df$ReadableDestination[df$ReadableDestination == "4"] <- "Psychiatric hospital or other psychiatric facility"
df$ReadableDestination[df$ReadableDestination == "5"] <- "Substance abuse treatment facility or detox center"
df$ReadableDestination[df$ReadableDestination == "6"] <- "Hospital or other residential non-psychiatric medical facility"
df$ReadableDestination[df$ReadableDestination == "7"] <- "Jail, prison or juvenile detention facility"
df$ReadableDestination[df$ReadableDestination == "8"] <- "Client doesn’t know"
df$ReadableDestination[df$ReadableDestination == "9"] <- "Client refused"
df$ReadableDestination[df$ReadableDestination == "10"] <- "Rental by client, no ongoing housing subsidy"
df$ReadableDestination[df$ReadableDestination == "11"] <- "Owned by client, no ongoing housing subsidy"
df$ReadableDestination[df$ReadableDestination == "12"] <- "Staying or living with family, temporary tenure (e.g., room, apartment or house)"
df$ReadableDestination[df$ReadableDestination == "13"] <- "Staying or living with friends, temporary tenure (e.g., room apartment or house)"
df$ReadableDestination[df$ReadableDestination == "14"] <- "Hotel or motel paid for without emergency shelter voucher"
df$ReadableDestination[df$ReadableDestination == "15"] <- "Foster care home or foster care group home"
df$ReadableDestination[df$ReadableDestination == "16"] <- "Place not meant for habitation (e.g., a vehicle, an abandoned building, bus/train/subway station/airport or anywhere outside)"
df$ReadableDestination[df$ReadableDestination == "17"] <- "Other"
df$ReadableDestination[df$ReadableDestination == "18"] <- "Safe Haven"
df$ReadableDestination[df$ReadableDestination == "19"] <- "Rental by client, with VASH housing subsidy"
df$ReadableDestination[df$ReadableDestination == "20"] <- "Rental by client, with other ongoing housing subsidy"
df$ReadableDestination[df$ReadableDestination == "21"] <- "Owned by client, with ongoing housing subsidy"
df$ReadableDestination[df$ReadableDestination == "22"] <- "Staying or living with family, permanent tenure"
df$ReadableDestination[df$ReadableDestination == "23"] <- "Staying or living with friends, permanent tenure"
df$ReadableDestination[df$ReadableDestination == "24"] <- "Deceased"
df$ReadableDestination[df$ReadableDestination == "25"] <- "Long-term care facility or nursing home"
df$ReadableDestination[df$ReadableDestination == "26"] <- "Moved from one HOPWA funded project to HOPWA PH"
df$ReadableDestination[df$ReadableDestination == "27"] <- "Moved from one HOPWA funded project to HOPWA TH"
df$ReadableDestination[df$ReadableDestination == "28"] <- "Rental by client, with GPD TIP housing subsidy"
df$ReadableDestination[df$ReadableDestination == "29"] <- "Residential project or halfway house with no homeless criteria"
df$ReadableDestination[df$ReadableDestination == "30"] <- "No exit interview completed"
df$ReadableDestination[df$ReadableDestination == "99"] <- "Data not collected"
df
}
makeProjectTypeReadable <- function (df) {
df <- sqldf("SELECT *, ProjectType as 'ReadableProjectType' FROM df")
df$ReadableProjectType[df$ReadableProjectType == "1"] <- "Emergency Shelter"
df$ReadableProjectType[df$ReadableProjectType == "2"] <- "Transitional Housing"
df$ReadableProjectType[df$ReadableProjectType == "3"] <- "PH - Permanent Supportive Housing"
df$ReadableProjectType[df$ReadableProjectType == "4"] <- "Street Outreach"
df$ReadableProjectType[df$ReadableProjectType == "5"] <- "Services Only"
df$ReadableProjectType[df$ReadableProjectType == "6"] <- "Other"
df$ReadableProjectType[df$ReadableProjectType == "7"] <- "Safe Haven"
df$ReadableProjectType[df$ReadableProjectType == "8"] <- "PH – Housing Only"
df$ReadableProjectType[df$ReadableProjectType == "10"] <- "PH – Housing with Services (no disability required for entry)"
df$ReadableProjectType[df$ReadableProjectType == "11"] <- "Day Shelter"
df$ReadableProjectType[df$ReadableProjectType == "12"] <- "Homelessness Prevention"
df$ReadableProjectType[df$ReadableProjectType == "13"] <- "PH - Rapid Re-Housing"
df$ReadableProjectType[df$ReadableProjectType == "14"] <- "Coordinated Assessment"
df
}
makeRaceReadable <- function(client){
client$AmIndAKNativ[client$AmIndAKNative == "1"] <- "American Indian or Alaska Native"
client$Asian[client$Asian == "1"] <- "Asian"
client$BlackAfAmerican[client$BlackAfAmerican == "1"] <- "Black or African American"
client$NativeHIOtherPacific[client$NativeHIOtherPacific == "1"] <- "Native Hawaiian or Other Pacific Islander"
client$White[client$White == "1"] <- "White"
client$RaceNone[client$RaceNone == "8"] <- "Client doesnt know"
client$RaceNone[client$RaceNone == "9"] <- "Client refused"
client$RaceNone[client$RaceNone == "99"] <- "Data not collected"
client
}
makeGenderReadable <- function(client) {
# HMIS CSV 5.1
# 0 Female
# 1 Male
# 2 Transgender male to female
# 3 Transgender female to male
# 4 Doesn’t identify as male, female, or transgender
# 8 Client doesn’t know
# 9 Client refused
# 99 Data not collected
client$Gender[client$Gender == "0"] <- "Female"
client$Gender[client$Gender == "1"] <- "Male"
client$Gender[client$Gender == "2"] <- "Transgender male to female"
client$Gender[client$Gender == "3"] <- "Transgender female to male"
client$Gender[client$Gender == "4"] <- "Doesn’t identify as male, female, or transgender"
client$Gender[client$Gender == "8"] <- "Client doesn’t know"
client$Gender[client$Gender == "9"] <- "Client refused"
client$Gender[client$Gender == "99"] <- "Data not collected"
client
}
makeVeteranStatusReadable <- function(client) {
# HMIS CSV 5.1
# 0 No
# 1 Yes
# 8 Client doesn’t know
# 9 Client refused
# 99 Data not collected
client$VeteranStatus[client$VeteranStatus == "0"] <- "No"
client$VeteranStatus[client$VeteranStatus == "1"] <- "Yes"
client$VeteranStatus[client$VeteranStatus == "8"] <- "Client doesn’t know"
client$VeteranStatus[client$VeteranStatus == "9"] <- "Client refused"
client$VeteranStatus[client$VeteranStatus == "99"] <- "Data not collected"
client
}
makeEthnicityReadable <- function(client) {
# HMIS CSV 5.1
# 0 Non-Hispanic/Non-Latino
# 1 Hispanic/Latino
# 8 Client doesn’t know
# 9 Client refused
# 99 Data not collected
client$Ethnicity[client$Ethnicity == "0"] <- "Non-Hispanic/Non-Latino"
client$Ethnicity[client$Ethnicity == "1"] <- "Hispanic/Latino"
client$Ethnicity[client$Ethnicity == "8"] <- "Client doesn’t know"
client$Ethnicity[client$Ethnicity == "9"] <- "Client refused"
client$Ethnicity[client$Ethnicity == "99"] <- "Data not collected"
client
}
combineRaceColumnsAndMakeReadable <- function(client){
client$AmIndAKNativ[client$AmIndAKNative == "0"] <- ""
client$Asian[client$Asian == "0"] <- ""
client$BlackAfAmerican[client$BlackAfAmerican == "0"] <- ""
client$NativeHIOtherPacific[client$NativeHIOtherPacific == "0"] <- ""
client$White[client$White == "0"] <- ""
client$RaceNone[client$RaceNone == "0"] <- ""
client <- makeRaceReadable(client)
client$Race <- paste(client$AmIndAKNativ, client$Asian, client$BlackAfAmerican, client$NativeHIOtherPacific, client$White, client$RaceNone, sep = " ")
client$Race <- gsub(" NA", "",client$Race)
client <- client[,-which(names(client) == "AmIndAKNative")]
client <- client[,-which(names(client) == "Asian")]
client <- client[,-which(names(client) == "BlackAfAmerican")]
client <- client[,-which(names(client) == "NativeHIOtherPacific")]
client <- client[,-which(names(client) == "White")]
client <- client[,-which(names(client) == "RaceNone")]
client
}
addDisabilityInfoToClient <- function(client, disabilities){
# From HMIS CSV Programming Specifications 5.1
# 5 = Physical disability
clientsWithPhysicalDisability <- sqldf("SELECT *, 'Yes' As PhysicalDisability
FROM disabilities
WHERE DisabilityType = 5
AND DisabilityResponse = 1
")
clientsWithPhysicalDisability <- getMostRecentRecordsPerId(clientsWithPhysicalDisability, "PersonalID", "InformationDate")
client <- sqldf("SELECT a.*, b.PhysicalDisability
FROM client a
LEFT JOIN clientsWithPhysicalDisability b
ON a.PersonalID=b.PersonalID
")
client <- subset(client)
# 6 Developmental disability
clientDevelopmentalDisability <- sqldf("SELECT *, 'Yes' As DevelopmentalDisability
FROM disabilities
WHERE DisabilityType = 6
AND DisabilityResponse = 1
")
clientDevelopmentalDisability <- getMostRecentRecordsPerId(clientDevelopmentalDisability, "PersonalID", "InformationDate")
clientDevelopmentalDisability <- subset(clientDevelopmentalDisability)
client <- sqldf("SELECT a.*, b.DevelopmentalDisability
FROM client a
LEFT JOIN clientDevelopmentalDisability b
ON a.PersonalID=b.PersonalID
")
client <- subset(client)
# 7 Chronic health condition
clientChronicHealthCondition <- sqldf("SELECT *, 'Yes' As ChronicHealthCondition
FROM disabilities
WHERE DisabilityType = 7
AND DisabilityResponse = 1
")
clientChronicHealthCondition <- getMostRecentRecordsPerId(clientChronicHealthCondition, "PersonalID", "InformationDate")
client <- sqldf("SELECT a.*, b.ChronicHealthCondition
FROM client a
LEFT JOIN clientChronicHealthCondition b
ON a.PersonalID=b.PersonalID
")
client <- subset(client)
# 8 HIV/AIDS
clientHivAids <- sqldf("SELECT *, 'Yes' As 'HIV/AIDS'
FROM disabilities
WHERE DisabilityType = 8
AND DisabilityResponse = 1
")
clientHivAids <- getMostRecentRecordsPerId(clientHivAids, "PersonalID", "InformationDate")
client <- sqldf("SELECT a.*, b.'HIV/AIDS'
FROM client a
LEFT JOIN clientHivAids b
ON a.PersonalID=b.PersonalID
")
client <- subset(client)
# 9 Mental health problem
clientMentalHealthProblem <- sqldf("SELECT *, 'Yes' As MentalHealthProblem
FROM disabilities
WHERE DisabilityType = 9
AND DisabilityResponse = 1
")
clientMentalHealthProblem <- getMostRecentRecordsPerId(clientMentalHealthProblem, "PersonalID", "InformationDate")
client <- sqldf("SELECT a.*, b.MentalHealthProblem
FROM client a
LEFT JOIN clientMentalHealthProblem b
ON a.PersonalID=b.PersonalID
")
client <- subset(client)
# 10 Substance abuse
clientSubstanceAbuse <- sqldf("SELECT *, 'Yes' As SubstanceAbuse
FROM disabilities
WHERE DisabilityType = 10
AND DisabilityResponse = 1
")
clientSubstanceAbuse <- getMostRecentRecordsPerId(clientSubstanceAbuse, "PersonalID", "InformationDate")
client <- sqldf("SELECT a.*, b.SubstanceAbuse
FROM client a
LEFT JOIN clientSubstanceAbuse b
ON a.PersonalID=b.PersonalID
")
client <- subset(client)
client
}
makeDisabilityTypeReadable <- function(disabilities){
# From HMIS CSV Programming Specifications 5.1
# 5 Physical disability
# 6 Developmental disability
# 7 Chronic health condition
# 8 HIV/AIDS
# 9 Mental health problem
# 10 Substance abuse
disabilities$DisabilityType[disabilities$DisabilityType == "5"] <- "Physical disability"
disabilities$DisabilityType[disabilities$DisabilityType == "6"] <- "Developmental disability"
disabilities$DisabilityType[disabilities$DisabilityType == "7"] <- "PhysicalChronic health condition"
disabilities$DisabilityType[disabilities$DisabilityType == "8"] <- "Chronic health condition"
disabilities$DisabilityType[disabilities$DisabilityType == "9"] <- "HIV/AIDS"
disabilities$DisabilityType[disabilities$DisabilityType == "10"] <- "Substance abuse"
disabilities
}
makeTrackingMethodReadable <- function(df) {
df <- sqldf("SELECT *, ProjectType as 'ReadableTrackingMethod' FROM df")
df$ReadableProjectType[df$ReadableProjectType == "0"] <- "Entry/Exit Date"
df$ReadableProjectType[df$ReadableProjectType == "3"] <- "Night-by-Night"
}
# activeRecords <- activeFilter(df, "occStartDate", "occEndDate", "2017-01-23", '2017-01-26')
activeFilter <- function(df, dateVector1, dateVector2, beginRange, endRange){
df[is.na(df)] <- ""
df[dateVector1,] <- as.character(df[dateVector1,])
df[dateVector2,] <- as.character(df[dateVector2,])
str <- paste("SELECT * FROM df WHERE (", dateVector1, "< '", endRange, "' AND ", dateVector2, " = '') OR (", dateVector1, "< '", endRange, "' AND ", dateVector2, " > '", beginRange, "')", sep = "")
sqldf(str)
}
# Get active Enrollments
getActiveHudEnrollments <- function(enrollment, exit, project){
project <- makeProjectTypeReadable(project)
project <- subset(project)
activeEnrollment <- sqldf("SELECT *
FROM enrollment a
LEFT JOIN exit b
ON a.ProjectEntryID=b.ProjectEntryID
WHERE b.ProjectEntryID IS NULL")
activeEnrollment <- subset(activeEnrollment)
activeEnrollmentsWithProjectInfo <- sqldf("SELECT b.ProjectType, b.ReadableProjectType, b.ProjectID, b.ProjectName, a.*
FROM activeEnrollment a
INNER JOIN project b
ON a.ProjectID=b.ProjectID
")
activeEnrollmentsWithProjectInfo <- subset(activeEnrollmentsWithProjectInfo)
activeEnrollmentsWithProjectInfo
}
addProjectInfoToEnrollment <- function(enrollment, project){
project <- makeProjectTypeReadable(project)
enrollmentsWithProjectInfo <- sqldf("SELECT a.*, b.ProjectType, b.ReadableProjectType, b.ProjectName, b.TrackingMethod
FROM enrollment a
INNER JOIN project b
ON a.ProjectID=b.ProjectID
")
enrollmentsWithProjectInfo <- subset(enrollmentsWithProjectInfo)
enrollmentsWithProjectInfo
}
getMostRecentRecordsPerId <- function(df, idHeader, dateHeader){
str <- paste("SELECT *, MAX(", dateHeader, "), 'Yes' As Max", dateHeader, " FROM df GROUP BY ", idHeader, sep = "")
bfr <- sqldf(str)
sqldf(str)
}
getClientsInPH <- function(enrollment, exit, project) {
### START ###
#############################################
##### Active in PH Projects #################
############## Incomplete ###################
#############################################
project <- makeProjectTypeReadable(project)
project <- subset(project)
activeEnrollment <- sqldf("SELECT *
FROM enrollment a
LEFT JOIN exit b
ON a.ProjectEntryID=b.ProjectEntryID
WHERE b.ProjectEntryID IS NULL")
activeEnrollment <- subset(activeEnrollment)
activeEnrollmentsWithProjectInfo <- sqldf("SELECT b.ProjectType, b.ReadableProjectType, b.ProjectID, b.ProjectName, a.*
FROM activeEnrollment a
INNER JOIN project b
ON a.ProjectID=b.ProjectID
")
activeEnrollmentsWithProjectInfo <- subset(activeEnrollmentsWithProjectInfo)
# PSH = 3
# RRH = 13
clientsActiveInPh <- sqldf("SELECT PersonalID, 'Yes' As 'ActiveInPH'
FROM activeEnrollmentsWithProjectInfo
WHERE ProjectType = 3
OR ProjectType = 13
")
clientsActiveInPh <- subset(clientsActiveInPh)
clientsActiveInPh
}
getClientsInPHWithinRange <- function(enrollment, exit, project, beginDate, endDate) {
enrollment$EntryDate <- as.character(enrollment$EntryDate)
exit$ExitDate <- as.character(exit$ExitDate)
project <- makeProjectTypeReadable(project)
project <- subset(project)
enrollmentWithProjectInfo <- sqldf("SELECT b.ProjectType, b.ReadableProjectType, b.ProjectID, b.ProjectName, a.*
FROM enrollment a
INNER JOIN project b
ON a.ProjectID=b.ProjectID
")
enrollmentWithProjectInfo <- subset(enrollmentWithProjectInfo)
str <- paste("SELECT * FROM enrollmentWithProjectInfo WHERE (ProjectType = 3 OR ProjectType = 13) AND EntryDate < '", beginDate, "'", sep = "")
phEnrollment <- sqldf(str)
str2 <- paste("SELECT * FROM exit WHERE ExitDate < '", endDate, "'", sep = "")
relevantExit <- sqldf(str2)
activeEnrollment <- sqldf("SELECT *
FROM phEnrollment a
LEFT JOIN relevantExit b
ON a.ProjectEntryID=b.ProjectEntryID
WHERE b.ProjectEntryID IS NULL")
######################################################################
######################################################################
######################################################################
###################### Left off Here #################################
######################################################################
######################################################################
######################################################################
}
getWeeksBetween <- function(beginDate, endDate){
difftime(strptime(endDate, format = "%Y-%m-%d"), strptime(beginDate, format = "%Y-%m-%d"), units="weeks")
}
getMonthsBetween <- function(beginDate, endDate){
(as.yearmon(strptime(endDate, format = "%Y-%m-%d"))-
as.yearmon(strptime(beginDate, format = "%Y-%m-%d")))*12
}
getQuartersBetween <- function(beginDate, endDate){
(as.yearqtr(strptime(endDate, format = "%Y-%m-%d"))-
as.yearqtr(strptime(beginDate, format = "%Y-%m-%d")))*4
}
getYearsBetween <- function(beginDate, endDate){
(as.yearmon(strptime(endDate, format = "%Y-%m-%d"))-
as.yearmon(strptime(beginDate, format = "%Y-%m-%d")))
}
addChronicallyHomelessFlagToClient <- function(client, enrollment){
#############################################
##### Get those with Disabling Condition ###
#############################################
enrolledWithDisability <- sqldf("SELECT *
FROM enrollment
WHERE DisablingCondition = 1")
#############################################
##### Length-of-Stay ########################
#############################################
# Participants who meet the length-of-stay in homelessness requirement
# Either through four or more occurences with cumulative duration exceeding a year
# Or a consequtive year.
# 113 = "12 Months"
# 114 = "More than 12 Months"
chronicityDf <- sqldf("SELECT *
FROM enrolledWithDisability
WHERE (TimesHomelessPastThreeYears = 4
AND (
MonthsHomelessPastThreeYears = 113
OR MonthsHomelessPastThreeYears = 114)
)
OR (CAST(JULIANDAY('now') - JULIANDAY(DateToStreetESSH) AS Integer) > 364
AND (DateToStreetESSH != '')
)
")
#############################################
##### Chronically Homeless ##################
#############################################
# Take the distinct PersonalIDs of individuals who meet both chronicity
# and disabling condition.
chClient <- sqldf("SELECT DISTINCT(PersonalID), 'Yes' As 'ChronicallyHomeless'
FROM chronicityDf
")
# Get client info for chronically homeless.
chClient <- sqldf("SELECT a.*, b.'ChronicallyHomeless'
FROM client a
LEFT JOIN chClient b
ON a.PersonalID=b.PersonalID
")
chClient <- subset(chClient)
chClient
}
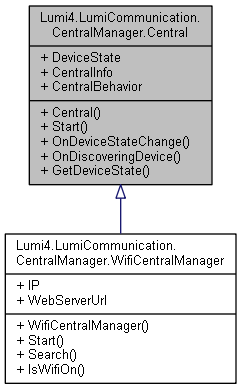
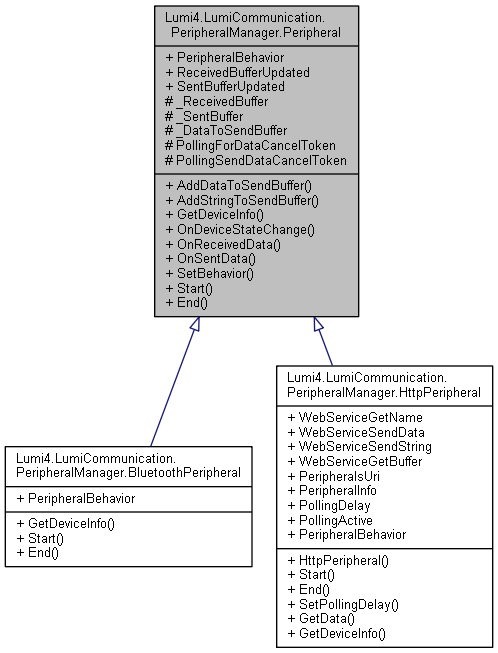
 However, when I started trying to add ESP8266 support–well, things went to the Pooh. It seemed of all the problems listed above the only one resolved was the adding of Bluetooth LE support. My skill was not increasing.
However, when I started trying to add ESP8266 support–well, things went to the Pooh. It seemed of all the problems listed above the only one resolved was the adding of Bluetooth LE support. My skill was not increasing.