
This article is part of a series.
View all 6 parts
- Part 1 – Creating a GPU Accelerated Deep-Learning Environment on Arch Linux
- Part 2 – Using Python, NodeJS, Angular, and MongoDB to Create a Machine Learning System
- Part 3 – Distributing Machine Learning Jobs
- Part 4 – This Article
- Part 5 – Preparing a Small Server for a Neural Network Webservice
- Part 6 – Creating a Neural Network Webservice
I'm writing learning-notes from implementing a "toxic comment" detector using a convolutional neural network (CNN). This is a common project across the interwebs, however, the articles I've seen on the matter leave a few bits out. So, I'm attempting to augment public knowledge--not write a comprehensive tutorial.
A common omission is what the data look like as they travel through pre-processing. I'll try to show how the data look before falling into the neural-net black-hole. However, I'll stop short before reviewing the CNN setup, as this is explained much better elsewhere. Though, I've put all the original code, relevant project links, tutorial links, and other resources towards the bottom.
The Code
Code: Imports
from __future__ import print_function
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Dense, Input, GlobalMaxPooling1D, Conv1D, Embedding, MaxPooling1D
from keras.models import Model
from keras.initializers import Constant
import gensim.downloader as api
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
The above code includes several packages which would need to be downloaded. The easiest way is to use pip .
pip install keras
pip install gensim
pip install pandas
Code: Variables
BASE_DIR = 'your project directory'
TRAIN_TEXT_DATA_DIR = BASE_DIR + 'train.csv'
MAX_SEQUENCE_LENGTH = 100
MAX_NUM_WORDS = 20000
EMBEDDING_DIM = 300
VALIDATION_SPLIT = 0.2
The above variables define the preprocessing actions and the neural-network.
TRAIN_TEXT_DATA_DIR
The directory containing the data file
train.csv
MAX_SEQUENCE_LENGTH
The toxic_comment data set contains comments collected from Wikipedia. MAX_SEQUENCE_LENGTH is used in the preprocessing stages to truncate a comment if too long. That is, greater than
MAX_SEQUENCE_LENGTH
. For example, a comment like:
You neeed to @#$ you mother!$@#$&...
Probably doesn't need much more for the network to discern it's a toxic comment. Also, if we create the network based around the longest comment, it will become unnecessarily large and slow. Much like the human brain (See Overchoice ), we need to provide as little information as needed to make a good decision.
MAX_NUM_WORDS
This variable is the maximum number of words to include--or, vocabulary size.
Much like truncating the sequence length, the maximum vocabulary should not be overly inclusive. The number
20,000
comes from a "study" stating an average person only uses 20,000 words. Of course, I've not found a primary source stating this--not saying it's not out there, but I've not found it yet. (Halfhearted search results in the appendix.)
Regardless, it seems to help us justify keeping the NN nimble.
EMBEDDING_DIM
In my code, I've used
gensim
to download pre-trained word embeddings. But beware, not all pre-trained embeddings have the same number of dimensions. This variables defines the size of the embeddings used.
Please note, if you use embeddings other than
glove-wiki-gigaword-300
you will need to change this variable to match.
VALIDATION_SPLIT
A helper function in Keras will split our data into a
test
and
validation
. This percentage represents how much of the data to hold back for validation.
Code: Load Embeddings
print('Loading word vectors.')
# Load embeddings
info = api.info()
embedding_model = api.load("glove-wiki-gigaword-300")
The
info
object is a list of
gensim
embeddings available. You can use any of the listed embeddings in the format
api.load('name-of-desired-embedding')
. One nice feature of
gensim
's
api.load
is it will automatically download the embeddings from the Internet and load them into Python. Of course, once they've been downloaded,
gensim
will load the local copy. This makes it easy to experiment with different embedding layers.
Code: Process Embeddings
index2word = embedding_model.index2word
vocab_size = len(embedding_model.vocab)
word2idx = {}
for index in range(vocab_size):
word2idx[index2word[index]] = index
The two dictionaries
index2word
and
word2idx
are key to embeddings.
The
word2idx
is a dictionary where the keys are the words contained in the embedding and the values are the integers they represent.
word2idx = {
"the": 0,
",": 1,
".": 2,
"of": 3,
"to": 4,
"and": 5,
....
"blah": 12984,
...
}
index2word
is a list where the the values are the words and the word's position in the string represents it's index in the
word2idx
.
index2word = ["the", ",", ".", "of", "to", "and", ...]
These will be used to turn our comment strings into integer vectors.
After this bit of code we should have three objects.
-
embedding_model-- Pre-trained relationships between words, which is a matrix 300 x 400,000. -
index2word-- A dictionary containingkey-valuepairs, the key being the word as a string and value being the integer representing the word. Note, these integers correspond with the index in theembedding_model. -
word2idx-- A list containing all the words. The index corresponds to the word's position in the word embeddings. Essentially, the reverse of theindex2word.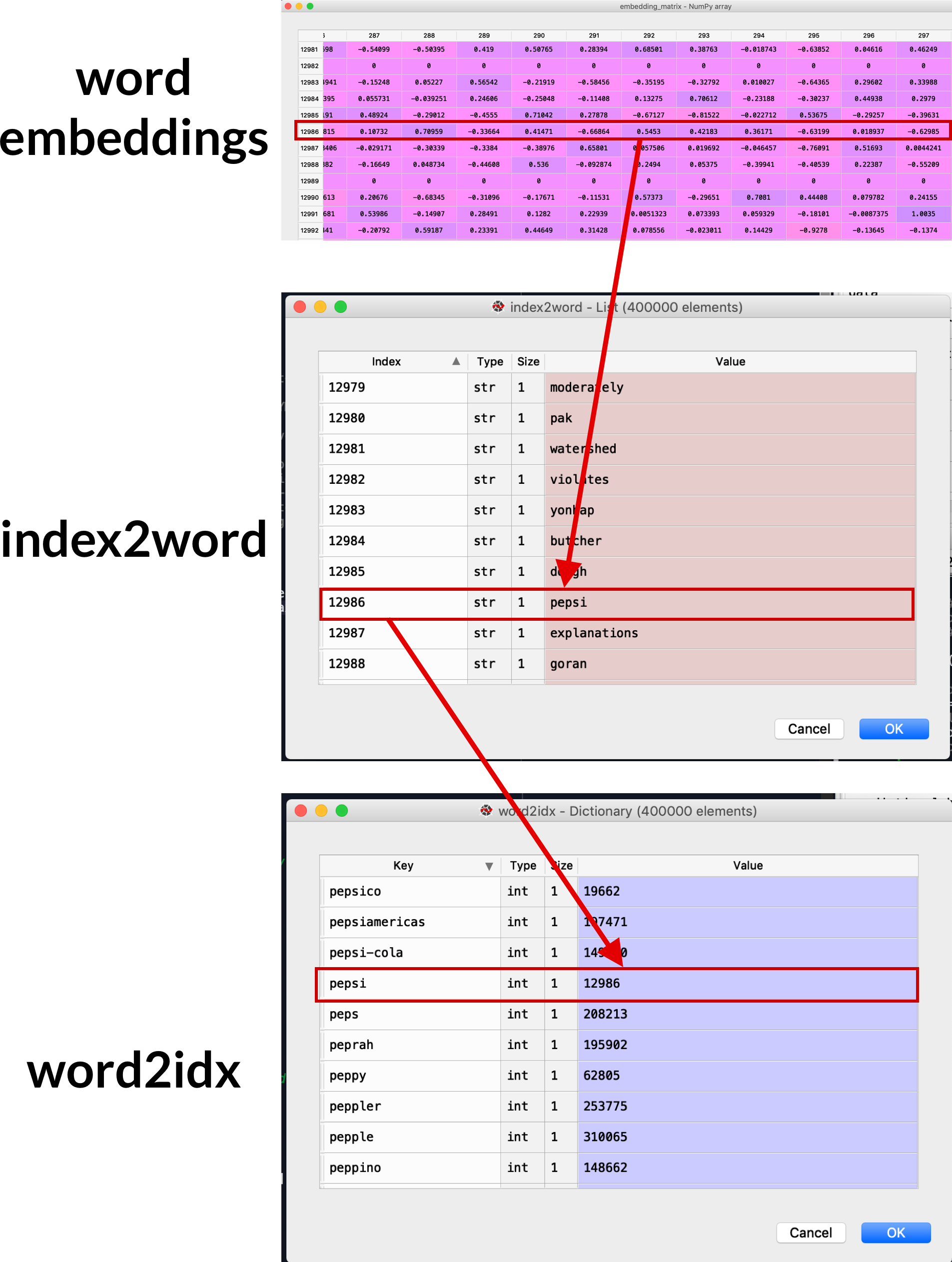

Code: Get Toxic Comments Labels
print('Loading Toxic Comments data.')
with open(TRAIN_TEXT_DATA_DIR) as f:
toxic_comments = pd.read_csv(TRAIN_TEXT_DATA_DIR)
print('Getting Comment Labels.')
prediction_labels = ["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]
labels = toxic_comments[prediction_labels].values
This loads the
toxic_comment.csv
as a Pandas dataframe called
toxic_comments
. We then grab all of the comment labels using their column names. This becomes a second a numpy matrix called
labels
.
We will use the text in the
toxic_comments
dataframe to predict the data found in the
labels
matrix. That is,
toxic_comments
will be our
x_train
and
labels
our
y_train
.
You may notice, the labels are also included in our
toxic_comments
. But they will not be used, as we will only be taking the
comment_text
column to become our
sequences
here in a moment.
toxic_comments
dataframe
| id | comment_text | toxic | severe_toxic | obscene | threat | insult | identity_hate | |
|---|---|---|---|---|---|---|---|---|
| 5 | 00025465d4725e87 | Congratulations from me as well, use the tools well. · talk | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0002bcb3da6cb337 | COCKSUCKER BEFORE YOU PISS AROUND ON MY WORK | 1 | 1 | 1 | 0 | 1 | 0 |
| 7 | 00031b1e95af7921 | Your vandalism to the Matt Shirvington article has been reverted. Please don't do it again, or you will be banned. | 0 | 0 | 0 | 0 | 0 | 0 |
labels
(
y_train
) numpy matrix
| 0 | 1 | 2 | 3 | 4 | 5 | |----|----|----|----|----|----|-----| | 0 | 0 | 0 | 0 | 0 | 0 | | 1 | 1 | 1 | 0 | 1 | 0 | | 0 | 0 | 0 | 0 | 0 | 0 | | 0 | 0 | 0 | 0 | 0 | 0 |
Code: Convert Comments to Sequences
print('Tokenizing and sequencing text.')
tokenizer = Tokenizer(num_words=MAX_NUM_WORDS)
tokenizer.fit_on_texts(toxic_comments['comment_text'].fillna("<DT>").values)
sequences = tokenizer.texts_to_sequences(toxic_comments['comment_text'].fillna("<DT>").values)
word_index = tokenizer.word_index
print('Found %s sequences.' % len(sequences))
The
Tokenizer
object comes from the
Keras
API. It takes chunks of texts cleans them and then converts them to unique integer values.
The
num_words
argument tells the Tokenizer to only preserve the word frequencies higher than this threshold. This makes it necessary to run the
fit()
on the targeted texts before using the Tokenizer. The fit function will determine the number of occurrences each word has throughout all the texts provided, then, it will order these by frequency. This frequency rank can be found in the
tokenizer.word_index
property.
For example, looking at the dictionary below, if
num_words
= 7 all words after "i" would be excluded.
{
"the": 1,
"to": 2,
"of": 3,
"and": 4,
"a": 5,
"you": 6,
"i": 7,
"is": 8,
...
"hanumakonda": 210334,
"956ce": 210335,
"automakers": 210336,
"ciu": 210337
}
Also, as we are loading the data, we are filling any missing values with a dummy token (i.e., "
na
values more strategically. Diminishing returns and all that.
Code: Padding
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
This is an easy one. It pads our sequences so they are all the same length. The
pad_sequences
function is part of the Keras library. A couple of important arguments have default values:
padding
and
truncating
.
Here's the Keras docs explanation:
padding: String, 'pre' or 'post': pad either before or after each sequence.
truncating: String, 'pre' or 'post': remove values from sequences larger than maxlen, either at the beginning or at the end of the sequences.
Both arguments default to
pre
.
Lastly, the
maxlen
argument controls where padding and truncation happen. And we are setting it with our
MAX_SEQUENCE_LENGTH
variable.

Code: Applying Embeddings
num_words = min(MAX_NUM_WORDS, len(word_index)) + 1
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
try:
embedding_vector = embedding_model.get_vector(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
except:
continue
Here's where stuff gets good. The code above will take all the words from our
tokenizer
, look up the word-embedding (vector) for each word, then add this to the
embedding matrix
. The
embedding_matrix
will be converted into a
keras.layer.Embeddings
object.
I think of an
Embedding
layer as a transformation tool sitting at the top of our neural-network. It takes the integer representing a word and outputs its word-embedding vector. It then passes the vector into the neural-network. Simples!
Probably best to visually walk through what's going on. But first, let's talk about the code before the
for-loop
.
num_words = min(MAX_NUM_WORDS, len(word_index)) + 1
This gets the maximum number of words to be addeded in our embedding layer. If it is less than our "average English speaker's vocabulary"--20,000--we'll use all of the words found in our tokenizer. Otherwise, the
for-loop
will stop after
num_words
is met. And remember, the
tokenizer
has kept the words in order of their frequency--so, the words which are lost aren't as critical.
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
This initializes our embedding_matrix, which is a
numpy
object with all values set to zero. Note, if the
EMBEDDING_DIM
size does not match the size of the word-embeddings loaded, the code will execute, but you will get a bad embedding matrix. Further, you might not notice until your network isn't training. I mean, not that this happened to
me
--I'm just guessing it could happen to
someone
.
for word, i in word_index.items():
try:
embedding_vector = embedding_model.get_vector(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
except:
continue
Here's where the magic happens. The
for-loop
iterates over the words in the
tokenizer
object
word_index
. It attempts to find the word in word-embeddings, and if it does, it adds the vector to the embedding matrix at a row respective to its index in the
word_index
object.
Confused? Me too. Let's visualize it.
Let's walk through the code with a word in mind: "of".
for word, i in word_index.items():
By now the
for-loop
is two words in. The words "the" and "to" have already been added. Therefore, for this iteration
word
= 'of' and
i
= 2.
embedding_vector = embedding_model.get_vector(word)
The the word-embedding for the word "of" is
-0.076947, -0.021211, 0.21271, -0.72232, -0.13988, -0.12234, ...
This list is contained in a
numpy.array
object.
embedding_matrix[i] = embedding_vector
Lastly, the word-embedding vector representing "of" gets added to the third row of the embedding matrix (the matrix index starts at 0).
Here's how the embedding matrix should look after the word "of" is added. (The first column added for readability.)
| word | 1 | 2 | 3 | 4 | ... |
|---|---|---|---|---|---|
| the | 0 | 0 | 0 | 0 | ... |
| to | 0.04656 | 0.21318 | -0.0074364 | -0.45854 | ... |
| of | -0.25756 | -0.057132 | -0.6719 | -0.38082 | ... |
| ... | ... | ... | ... | ... | ... |
Also, for a deep visualization, check the image above. The picture labeled "word embeddings" is
actually
the output of our
embedding_matrix
. The big difference? The word vectors in the
gensim
embedding_model which are not found anywhere in our corpus (all the text contained in the toxic_comments column) have been replaced with all zeroes.

Code: Creating Embedding Layer
embedding_layer = Embedding(len(word2idx),
EMBEDDING_DIM,
embeddings_initializer=Constant(embedding_matrix),
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)
Here we are creating the first layer of our NN. The primary parameter passed into the Keras
Embedding
class is the
embedding_matrix
, which we created above. However, there are several other attributes of the
embedding_layer
we must define. Keep in mind our
embedding_layer
will take an integer representing a word as input and output a vector, which is the word-embedding.
First, the
embedding_layers
needs to know the input dimensions. The input dimension is the number of words we are considering for this training session. This can be found by taking the length of our
word2idx
object. So, the
len(word2idx)
returns the total number of words to consider.
One note on the layer's input, there are two "input" arguments for
keras.layers.Embedding
class initializer, which can be confusing. They are
input
and
input_length
. The
input
is the number of possible values provided to the layer. The
input_length
is how many values will be passed in a sequence.
Here are the descriptions from the Keras documentation:
input
int > 0. Size of the vocabulary, i.e. maximum integer index + 1.
input_length
Length of input sequences, when it is constant. This argument is required if you are going to connect Flatten then Dense layers upstream (without it, the shape of the dense outputs cannot be computed).
In our case, the
input
will be the vocabulary size and
input_length
is the number of words in a sequence, which should be
MAX_SEQUENCE_LENGTH
. This is also why we padded comments shorter than
MAX_SEQUENCE_LENGTH
, as the embedding layer will expect a consistent size.
Next, the
embedding_layers
needs to know the dimensions of the output. The output is going to be a word-embedding vector, which
should
be the same size as the word embeddings loaded from the
gensim
library.
We defined this size with the
EMBEDDING_DIM
variable.
Lastly, the
training
option is set to
False
so the word-embedding relationships are not updated as we train our
toxic_comment
detector. You could set it to
True
, but come on, let's be honest, are we going to be doing better than Google?
Code: Splitting the Data
nb_validation_samples = int(VALIDATION_SPLIT * data.shape[0])
x_train = data[:-nb_validation_samples]
y_train = labels[:-nb_validation_samples]
x_val = data[-nb_validation_samples:]
y_val = labels[-nb_validation_samples:]
Here we are forming our data as inputs. We convert the
data
into
x_train
and
x_val
. The
labels
dataframe becomes
y_train
and
y_val
. And here marks the end of
pre-processing.
But! Let's recap before you click away:
- Load the word-embeddings. These are pre-trained word relationships. It is a matrix 300 x 400,000.
-
Create two look up objects:
index2wordandword2idx -
Get our
toxic_commentandlabelsdata. -
Convert the
commentscolumn fromtoxic_commentsdataframe into thesequenceslist. -
Create a
tokenizerobject and fit it to thesequencestext - Pad all the sequences so they are the same size.
-
Look up the word-embedding vector for each unique word in
sequences. Store the word-embedding vector in thembedding_matrix. If the word is not found in the embeddings, then leave the index all zeroes. Also, limit the embedding-matrix to the 20,000 most used words. -
Create a Keras
Embeddinglayer from theembedding_matrix - Split the data for training and validation.
And that's it. The the prepared
embedding_layer
will become the first layer in the network.
Code: Training
Like I stated at the beginning, I'm not going to review training the network, as there are many better explanations--and I'll link them in the Appendix. However, for those interested, here's the rest of the code.
input_ = Input(shape=(MAX_SEQUENCE_LENGTH,))
x = embedding_layer(input_)
x = Conv1D(128, 5, activation='relu')(x)
x = MaxPooling1D(5)(x)
x = Conv1D(128, 5, activation='relu')(x)
x = MaxPooling1D(5)(x)
x = Conv1D(128, 3, activation='relu')(x)
x = GlobalMaxPooling1D()(x)
x = Dense(128, activation='relu')(x)
output = Dense(len(prediction_labels), activation='sigmoid')(x)
model = Model(input_, output)
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
print('Training model.')
# happy learning!
history = model.fit(x_train, y_train, epochs=2, batch_size=512, validation_data=(x_val, y_val))
Oh! There's one more bit I'd like to go over, which most other articles have left out. Prediction.
Code: Predictions
I mean, training a CNN is fun and all, but how does one use it? Essentially, it comes down to repeating the steps above, but with with less data.
def create_prediction(model, sequence, tokenizer, max_length, prediction_labels):
# Convert the sequence to tokens and pad it.
sequence = tokenizer.texts_to_sequences(sequence)
sequence = pad_sequences(sequence, maxlen=max_length)
# Make a prediction
sequence_prediction = model.predict(sequence, verbose=1)
# Take only the first of the batch of predictions
sequence_prediction = pd.DataFrame(sequence_prediction).round(0)
# Label the predictions
sequence_prediction.columns = prediction_labels
return sequence_prediction
# Create a test sequence
sequence = ["""
Put your test sentence here.
"""]
prediction = create_prediction(model, sequence, tokenizer, MAX_SEQUENCE_LENGTH, prediction_labels)
The function above needs the following arguments:
* The pre-trained
model
. This is the Keras model we just trained.
* A
sequence
you'd like to determine whether it is "toxic".
* The
tokenizer
, which is used to encode the prediction sequence the same way as the training sequences.
*
max_length
must be the same as the maximum size of the training sequences
* The
prediction_labels
are a list of strings containing the human readable labels for the predicted tags (e.g. "toxic", "severe_toxic", "insult", etc.)
Really, the function takes all the important parts of our pre-processing and reuses them on the prediction sequence.
One piece of the function you might tweak is the
.round(0)
. I've put this there to convert the predictions into binary. That is, if prediction for a sequence is
.78
it is rounded up to
1
. This is do to the binary nature of the prediction. Either a comment is toxic or it is not. Either
0
or
1
.
Well, that's what I got. Thanks for sticking it out. Let me know if you have any questions.
Appendix
Full Code
Tutorials
- Convolutional Neural Networks for Toxic Comment Classification (Academic)
- Kaggle Projects Using a CNN and Toxicty Data
- Tutorial of Using Word Vectors
- Keras Tutorial on Using Pretrained Word Embeddings
If you want to know more about gensim and how it can be used with Keras. * Depends on the Definition
Data
The data are hosted by Kaggle.
Please note, you will have to sign-up for a Kaggle account.
Average Person's Vocabulary Size
Primary sources on vocabulary size: * How Many Words Do We Know? Practical Estimates of Vocabulary Size Dependent on Word Definition, the Degree of Language Input and the Participant’s Age * How Large Can a Receptive Vocabulary Be? * Toward a Meaningful Definition of Vocabulary Size * Vocabulary size revisited: the link between vocabulary size and academic achievement * How Many Words Do We Know? Practical Estimates of Vocabulary Size Dependent on Word Definition, the Degree of Language Input and the Participant’s Age